
In questo primo modulo vedremo alcuni concetti basilari del network, affronteremo i protocolli, le tipologie di reti, le porte, il routing, il firewall.
Internet è una tecnologia che ha rivoluzionato il mondo nel campo delle telecomunicazioni in vari settori, da quello economico a quello informatico e sociale sconvolgendo i parametri legati al modo di vivere. La parola “Internet” nasce dalla contradizione di Interconnected Networks (reti interconnesse), la cui unione rappresenta una rete unica. Internet va considerato come un nuovo modello comunicativo che permette la comunicazione a chiunque si connetta alla rete globale mediante un computer. La caratteristica fondamentale d’internet è che non ha un ente centrale che la controlli, a sanare questa mancanza ci sono degli organismi di normalizzazione che gestiscono l’evoluzione tecnica della rete: ISOC (Internet Society) e IAB (Internet Architetture Board).
La rete ha raggiunto in tempi brevi dimensioni planetarie anche grazie alla collaborazione spontanea di persone spinte dal desiderio o dall’esigenza di comunicare esperienze e competenze. Le caratteristiche più rilevanti di internet sono:
- basso costo;
- valore intrinseco delle informazioni;
- velocità di trasferimento;
- elaborazione delle informazioni.
Tra il 1962 e il 1968, in USA nasce l’Arpa (Advanced Research Project), una società che inizia a sperimentare le prime reti di computer, la commutazione di pacchetti dati e la condivisione di risorse.
Nel 1969 nasce Arpanet su commissione del dipartimento americano della difesa, l’agenzia telematica di ARPA avente quattro nodi di rete collegati tra loro.
I nodi erano:
- Università di Los Angeles;
- Università Utah;
- Università di Stanford;
- Università di S. Barbara.
Tra il1970 e il 1974 i nodi aumentano ad una decina, si studiano i primi protocolli di trasferimento dei dati e le prime tecnologie fisiche di collegamento tipo Ethernet per la rete Lan, nasce anche un protocollo di nome TCP (Transmission Control Protocol), nasce Telnet.
Tra il 1981 e 1983,il protocollo TCP/IP è sviluppato e adottato dal dipartimento della difesa americano.
Tra il 1984 e 1987,è studiato il sistema DNS (Domain Name System), nascono anche Nsfnet, rete della National Science Foundation che collega a 56kbs cinque centri di super calcolo. In questi anni nasce anche l’azienda Apple che distribuisce Hypercard, un ambiente per la costruzione d’ipertesti.
Nel 1988 è diffuso il primo virus di rete Internet worm, che infettò circa 6000 computer e nello stesso anno si sviluppa il sistema di chat Irc.
Tra il 1990 e 1991 Arpanet chiude, lasciando spazio alla nascita del sistema Gopher e del www (Word Wide Web), nascono anche i primi sistemi di crittografia dati SSL (secure sockets layer) .
Nel 1993 nasce il primo Browser grafico Mosaic per merito di Marc Andressen.
Nel 1994 Internet sviluppa i primi servizi commerciali, lo sviluppo fu ormai avviato e negli anni successivi non vide battute di arresto.
Fonte: Ebook Hackerpunk vol.1 profiling https://shorturl.at/jWZ06
Cos’è una rete? Il suo significato è posto in relazione con l’ambiente o il settore in cui essa è collocata. Avremo quindi varie tipologie di rete correlate al relativo settore o scienza che ne gestisce i parametri come: la rete stradale legata al codice della strada, rete topografica legata alla geografia, rete finanziaria legata all’economia, rete di comunicazione telefonica legata alle telecomunicazioni e così via. Il nostro ambiente è l’informatica: pertanto potremmo definire una rete di dati un insieme di dispositivi digitali come computer, smartphone, dispositivi IOT, router utilizzati per le comunicazioni e connessi tra loro per mezzo di cavi e antenne che comunicano attraverso una serie di protocolli (regole) e servizi (programmi) scambiandosi dati e condividendo risorse (file, periferiche, dati ecc).
Se entrassimo nel dettaglio della rete internet, per fare un esempio pratico, potremmo vedere che è composta da tantissime sottoreti di dimensioni ridotte rispetto ad essa: si chiamano LAN (reti locali) e MAN (reti metropolitane).
Le reti locali, come può essere appunto una rete domestica, aziendale o universitaria, sono legate dal vincolo dell’edificio o complesso di edifici che ne delimita la copertura, è di dimensioni medie-piccole rispetto alle reti metropolitane, la dimensione definisce la sua estensione misurata in metri attraverso i suoi collegamenti (cavo fibra, frequenze wifi, cavo doppino, cavo coassiale). Le reti locali sono inquadrate in un sistema di reti più vasto e complesso che gli permette di essere interconnessa a lunghe distanze con altre sue simili, in modo di consentire la comnicazione con due o più dispositivi appartenenti a due reti lan diverse. Queste comunicazioni avvengono grazie ai collegamenti di transito che generano le reti di lunga distanza come le reti metropolitane e le dorsali dette anche backbone.
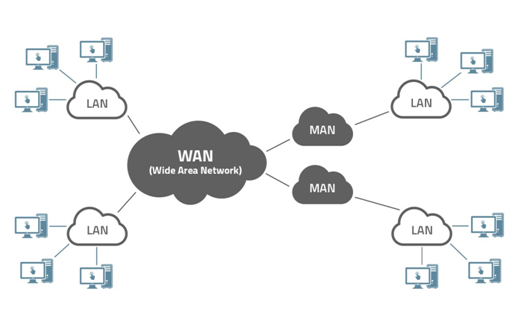
Per comprendere come avvengono i collegamenti tra architetture di rete diverse tra loro (per esempio, una rete LAN con una rete MAN) ci deve essere chiaro prima cos’è una connessione: è un insieme di canali, sistemi di commutazione e altri meccanismi funzionali configurati per fornire strumenti per il trasferimento dell’informazione tra due o più punti di una rete detti nodi, come per esempio: cavi, router e schede di rete.
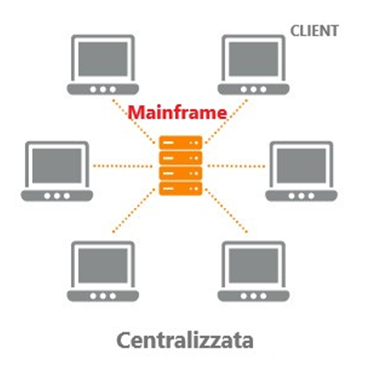
Negli anni Ottanta l’architettura di rete era centralizzata, negli anni successivi si sono evolute notevolmente fino a raggiungere quelle attuali, costituite da un’architettura client-server. Quella che si conosce sotto il nome di internet è la rete client-server più estesa che esiste, ma non è l’unica.
ARCHITETTURA CENTRALIZZATA
Era utilizzata negli anni 80, al centro della rete era posto un terminale “intelligente” chiamato anche Mainframe al quale erano connessi i terminali “stupidi”, quelli che non svolgevano calcoli affidando tutto il lavoro di elaborazione dei dati alla grossa macchina mainframe (per macchina si intende il computer).
I Mainframe creati dalla nota casa produttrice informatica IBM ebbero un notevole successo, garantendosi una grossa fetta di mercato in questo settore.
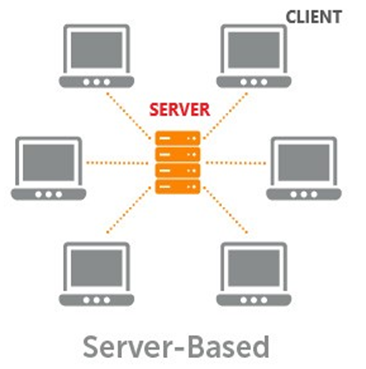
ARCHITETTURA CLIENT-SERVER
In questa struttura di rete tutti i computer sono elaboratori, svolgono calcoli ed elaborazione di dati, si collegano ai server, i quali forniscono servizi ad-hoc condividendo risorse come la messaggistica email, sms, spazio Hosting (siti web); Cloud service ecc.
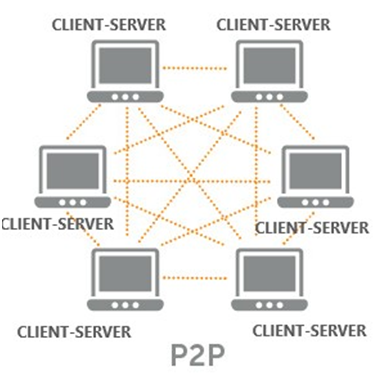
ARCHITETTURA PEER-TO-PEER
É una rete a maglia, tutti gli elaboratori svolgono simultaneamente il ruolo di client e server, condividendo le proprie risorse, i propri applicativi e i servizi: un esempio sono le reti torrent. Attualmente anche alcuni browser stanno sperimentando la decentralizzazione dei server attraverso un nuovo protocollo IPTS che sfrutta il p2p, uno di questi è il browser Brave, basta scaricarlo e installarlo per provarlo con mano.
Dal punto di vista topologico le reti sono classificate in:
- Rete a bus: consiste in un singolo cavo che connette in modo lineare tutti i computer, i dati sono inviati a tutti i computer e sono accettati solo dall’elaboratore il cui indirizzo è contenuto nel segnale di origine;
- Rete ad anello: è una rete a bus chiuso su sè stesso, i computer connessi da un unico cavo circolare.Un esempio è dato dalle reti in fibra ottica metropolitane (MAN). In reti più piccole i dati sono inviati in senso orario lungo il circuito chiuso, passando attraverso ciascun computer che funge anche da ripetitore, il segnale è detto Token è trasferito da un computer all’altro della rete finché non trova quello di destinazione. È possibile aggiungere un secondo anello in direzione opposta migliorando l’affidabilità in caso di guasto di una stazione o taglio accidentale di un cavo dell’anello primario;
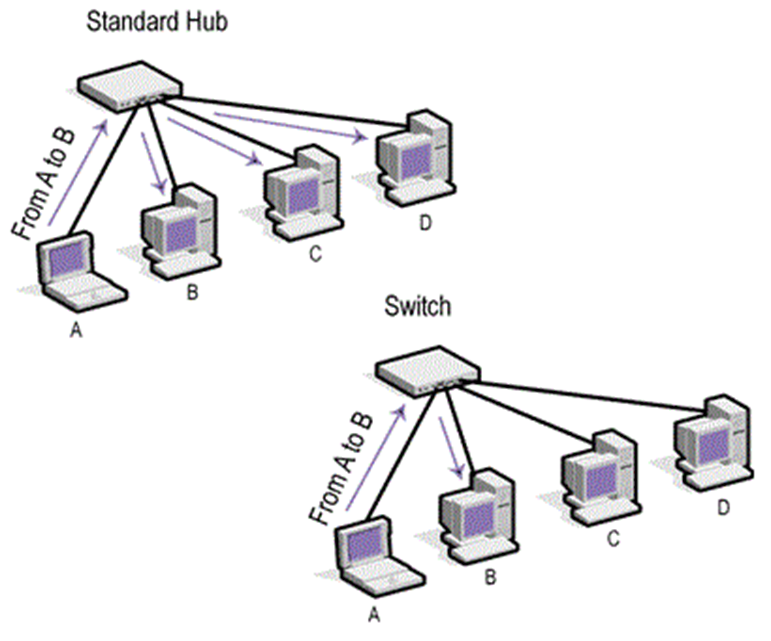
- Rete a stella: i computer sono connessi a un membro centrale chiamato Hub o Switch, detti anche concentratori, i dati sono inviati dal computer trasmittente attraverso l’hub a tutti i computer della rete, ma il segnale sarà captato dal solo computer destinatario. Invece, nel caso dello switch i dati saranno inviati direttamente al computer destinatario omettendo di inviare inutilmente il segnale a tutti i computer della rete:
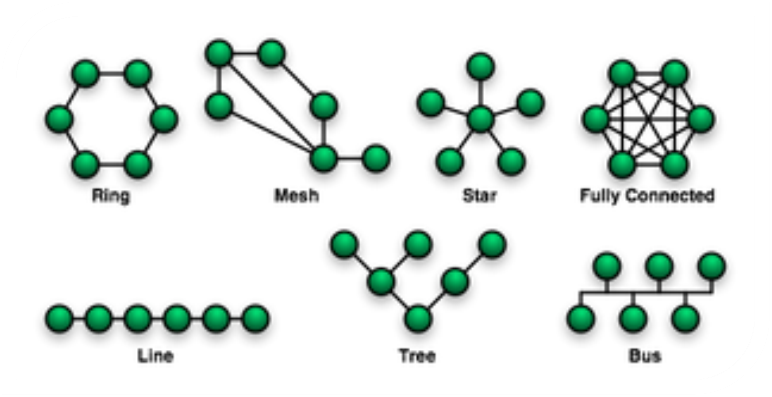
Dal punto di vista geografico e dell’estensione le reti sono classificate in:
- Wpan (Wireless Personal Area Network): in telecomunicazioni, una rete personale Pan è una rete informatica utilizzata per permettere la comunicazione tra diversi dispositivi vicino ad un singolo utente. I singoli dispositivi possono anche non appartenere all’utente in questione. Il raggio di azione di una rete PAN è tipicamente di alcuni metri: un esempio di rete PAN è la rete Bluetooth;
- Lan/Wlan (Local Area Network/Wireless Local Area Network): si tratta di una rete informatica di collegamento tra dispositivi, estendibile anche a quelli periferici condivisi, copre un’area limitata nel raggio massimo di 1-2 km di estensione come: scuola, azienda, complesso di edifici. La sua variante Wlan prevede collegamenti senza fili con tecnologia wireless;
- Man (Metropolitan Area Network): si tratta di una rete di trasporto, si estende per 2-10 km, questo tipo di rete può essere circoscritta in grosse metropoli e città principali. In passato è stata usata per trasportare servizi tv via cavo nelle abitazioni che avevano poca ricezione di segnale, attualmente sono interconnesse tra di loro dando vita alla rete Wan;
- Wan (Word Area Network):si tratta di una rete di trasporto e contiene al suo interno più reti Locali e Metropolitane, si estende per 10-10000 km, la più grande rete Wan mai realizzata è Internet che copre l’intero globo. Un altro esempio di rete Wan di ambito privato è la rete Garr.
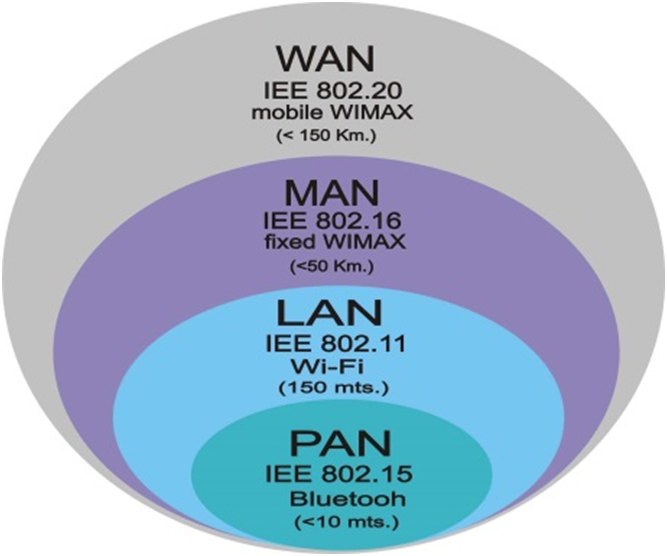
Fonte: Ebook Hackerpunk vol.1 profiling https://shorturl.at/jWZ06
Uno standard è una particolare metodologia da seguire in determinati sistemi, nel sistema di trasmissione dati in internet questi metodi sotto il nome di protocolli, racchiudono particolari regole che adottano i computer collegati in rete per scambiarsi dati tra loro attraverso il mezzo di trasmissione che condividono (doppino, fibra, wireless).
Per capire meglio questo concetto, basti immaginare due persone che non parlano la stessa lingua (quindi stesso protocollo): se un giapponese parlasse con un russo non riuscirebbero a comprendersi. Lo stesso discorso vale per protocolli utilizzati dai servizi di rete, i dati devono viaggiare con gli stessi protocolli di partenza e di arrivo o non funzionerebbe nulla: si pensi ad una sessione di navigazione e all’utilizzo simultaneo della posta elettronica, ovviamente se i dati non venissero trasmessi con i relativi protocolli non si riuscirebbe a visitare un sito web e contemporaneamente leggere la propria posta elettronica su Gmail. I principali standard di protocolli chiamati così perché racchiudono un sottoinsieme di protocolli sono:
- CSMA /CD;
- TOKEN PASSING;
- ISO/OSI;
- TCP/IP.
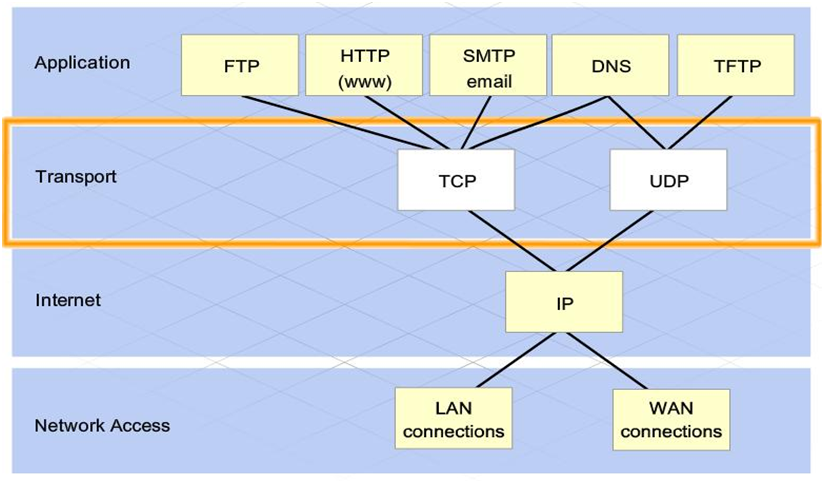
Lo standard CSMA/CD e Token passing sono utilizzati in reti LAN, non li vedremo, ma ci concentreremo in particolare sullo standard TCP/IP (Trasmission Control Protocol) poiché è il più importante, in quanto su di esso si basa tutta la comunicazione di dati in rete internet. Per comprenderlo bisogna analizzare prima il modello padre dal quale deriva, ovvero ISO/OSI (Open Systems Interconnections), TCP/IP non è altro che una sua semplificazione che ottimizza diminuendo gran parte dei livelli dell’ISO/OSI: https://wikipedia.org/wiki/Modello_Osi
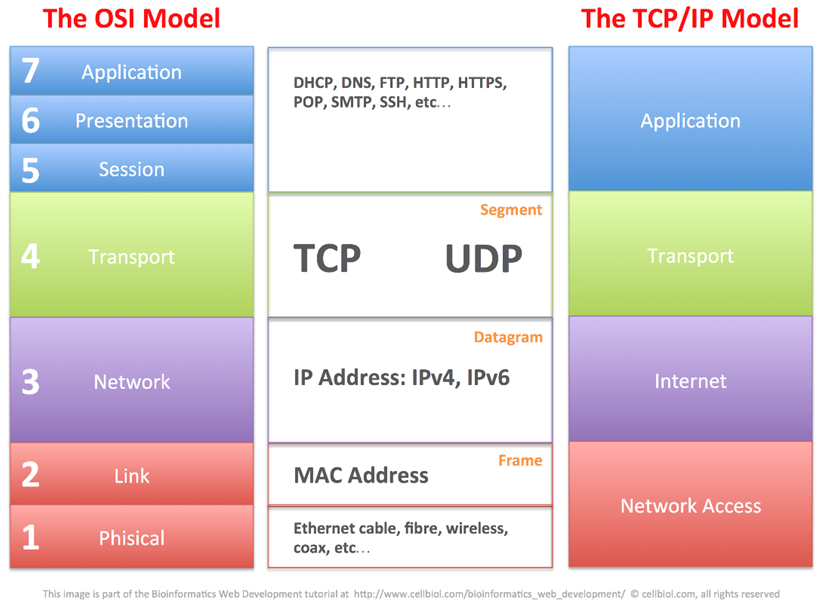
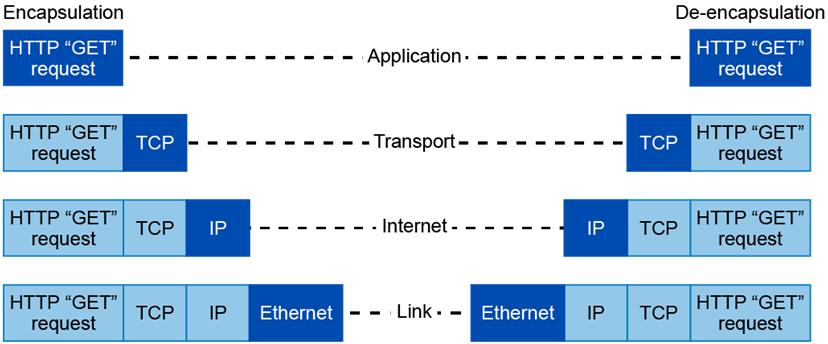
Il modello TCP/IP a differenza di ISO/OSI ha unicamente quattro livelli, i 3 livelli più alti dello standard OSI (application, presentation e session) sono assorbiti dal layer application, i 2 livelli più bassi (Phisical e data link) sono integrati all’interno del layer Network access. I livelli, detti anche layer, sono aree che delimitano le regole di trasporto e consegna dei dati sottoforma di pacchetto. La modalità di trasmissione di pacchetti da una rete locale ad un’altra mediante internet prende il nome di sistema commutazione a pacchetto: a differenza della commutazione di circuito dei segnali nella rete telefonica. I layer della pila OSI si possono paragonare agli step inquadrati all’interno di un servizio di corrispondenza postale come illustrato nella seguente immagine.
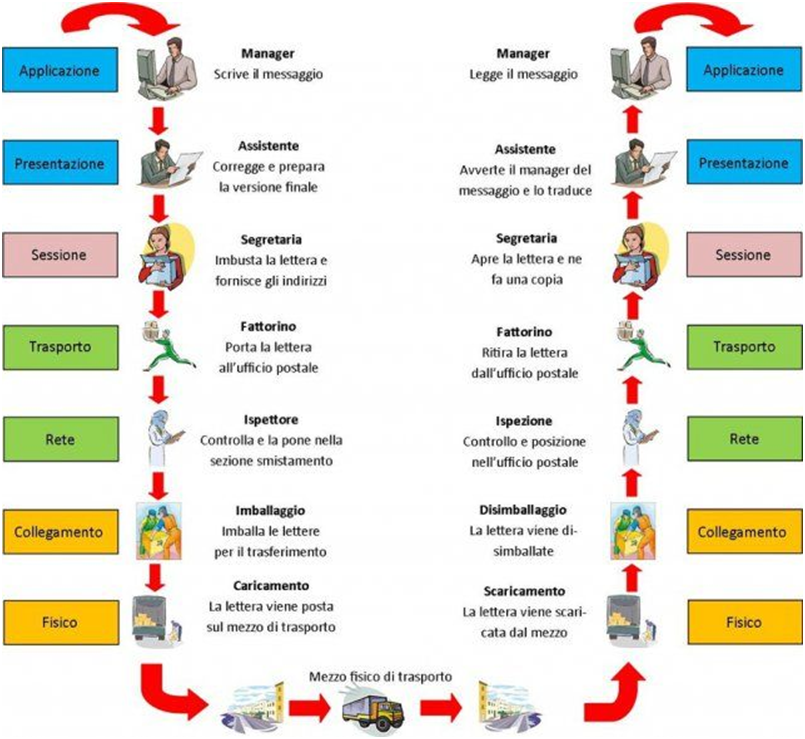
Fonte: Ebook Hackerpunk vol.1 profiling https://shorturl.at/jWZ06
Ogni protocollo dello standard TCP/IP in base al proprio posizionamento nel layer di riferimento (application, transport, internet, access) fa uso di una porta virtuale identificata da un numero compreso in un intervallo tra 0 e 65536 che indicano un intervallo di porte di default utilizzate dai servizi di rete. Di seguito alcune delle porte più importanti:
| PORTA | PROT.LLO TRASPORTO | PROT.LLO SERVIZIO/APPLICAZIONE |
| 20 | TCP | FTP data |
| 21 | TCP | FTP control |
| 22 | TCP | SSH |
| 23 | TCP | TELNET |
| 25 | TCP | SMTP |
| 53 | UDP/TCP | DNS |
| 67,68 | UDP | DHCP |
| 69 | UDP | TFTP |
| 80 | TCP | HTTP |
| 110 | TCP | POP3 |
| 161 | UDP | SNMP |
| 443 | TCP | HTTPS - SSL |
Le porte sono gestite dai Router, ovvero dispositivi hardware intelligenti che racchiudono al loro interno diversi componenti e funzionalità tra i quali:
- Switch (instradamento e protezione antispoofing);
- DTE (conversione segnali digitali in analogici e viceversa);
- ACL (access control list);
- Firewall/IPS (intrusion prevention system e packet filtering);
- Routing (traporto dei pacchetti tramite algoritmi e tabelle);
- Port forwarding (gestione delle porte).
I router lavorano sul layer 3° Network del modello ISO/OSI e possono collegare una rete locale ad un’altra remota attraverso altri router sparsi per internet. Nelle architetture di reti aziendali si preferisce far uso di molteplici router e switch per collegare aree dislocate su più piani o edifici diversi.
Un firewall è un software installato all’interno del router o anche nel sistema operativo (personal firewall) e servono per proteggere i dispositivi e in generale la rete interna dalle intrusioni di malintenzionati, come fossero delle vere e proprie barriere. Immaginiamo che firewall anche se non lo si vede materialmente perchè è un software è situato in senso logico tra il router e la rete internet. Tre sono le principali tipologie di firewall:
- Packet filter firewall;
- Proxy firewall;
- Stateful packet inspection firewall.
Quelli più comunemente utilizzati in ambito domestico, ma anche aziendale sono i packet filter che svolgono funzioni di filtraggio di pacchetti dati che provengono o sono diretti dalla rete internet verso la rete Lan o viceversa.
Le porte sono utilizzate dai nostri dispositivi collegati al router in rete locale per interagire tra loro, dai programmi per inviare dati o semplicemente rimanere in ascolto per riceverli. Gli switch lavorano sul layer 2° Data link del modello ISO/OSI e instradano il flusso di traffico di pacchetti IP in ingresso indirizzandoli verso i dispositivi della rete stessa, mentre i router instradano i pacchetti in uscita dalla rete locale indirizzandoli all’esterno attraverso la rete internet e i relativi nodi.
I servizi e i programmi in esecuzione sui computer possono aprire in automatico una porta a seconda della necessità dei pacchetti che vi dovranno transitare. Il viaggio dei pacchetti dati verso la rete internet inizia dal router detto anche Gateway, fino ad arrivare all’applicazione del destinatario seguendo le regole precise dello standard TCP/IP che gestirà il trasporto e la regolare consegna dei pacchetti IP.
Le porte possono essere aperte anche manualmente andando a modificare le configurazioni nel pannello di controllo del router attraverso un’attività chiamata Port forwarding.
Per comprendere bene il concetto delle porte si fa presente l’esempio della rete di computer paragonata ad una rete stradale:
- Gli indirizzi IP corrisponderanno ai nomi delle vie,
- le porte corrisponderanno ai numeri civici,
- i router corrisponderanno ai vari corrieri che dovranno scambiarsi il pacco per la consegna,
- il pacco potrà essere paragonato al pacchetto IP che conterrà il messaggio vero e proprio.
La sezione sul pacchetto dati in cui saranno indicati gli indirizzi IP del mittente e destinatario prende il nome di header che si può paragonarlo alla postilla impressa sulla raccomandata postale.
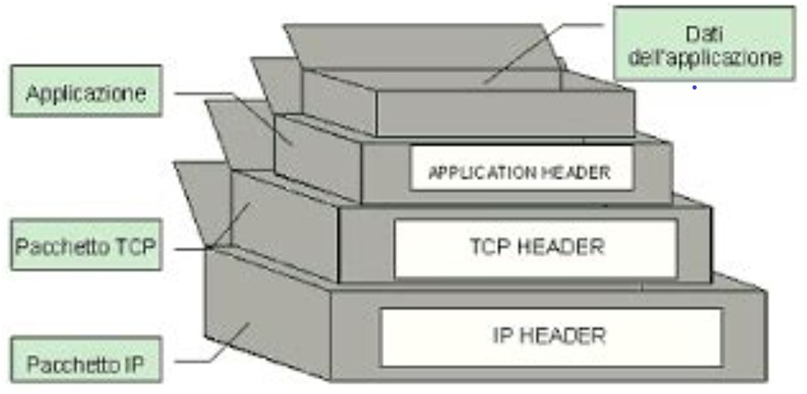
Man mano che un pacchetto dati (payload) attraversa i vari layer della pila OSI, ogni layer assegna un header al pacchetto, questo processo prende il nome di incapsulamento e lo rimuove ad ogni pacchetto in entrata al destinatario, decapsulamento. Per il momento daremo maggior risalto ai primi 4 livelli della pila OSI, in quanto sono quelli in cui avviene la formazione e la relativa trasmissione di un pacchetto dati. Per lo scopo sarà utile da tenere a mente la seguente tabella per comprendere in quale layer lavorano i dispositivi di rete e con quali sistemi trattano il trasporto dei pacchetti dati:
| LAYER | COMPONENTI DI RETE | SISTEMA |
| Phisical | hub, scheda di rete, cavi, wifi | segnali elettrici |
| Data Link | Switch | indirizzo MAC |
| Network | Router | Indirizzo IP |
| Transport | Socket | IP: porta |
Fonte: Ebook Hackerpunk vol.1 profiling https://shorturl.at/jWZ06
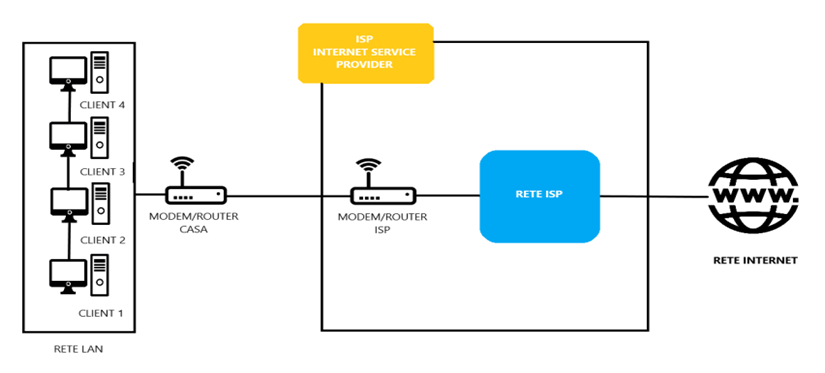
Nel paragrafo precendente abbiamo accennato che in una rete WAN come può essere la rete internet, l’indirizzo IP è assegnato dinamicamente dall’ISP (internet service provider) di appartenenza. In una rete locale come viene assegnato l’indirizzo IP?
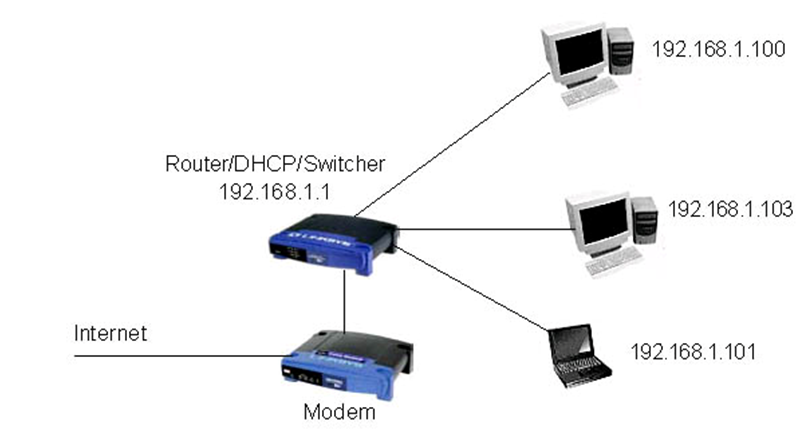
In rete locale le cose poi non sono così diverse, l’indirizzo IP è assegnato dal proprio router ai vari dispositivi ad esso collegati: il protocollo che gestisce questo meccanismo è il DHCP. Questo sistema regola le assegnazioni in una rete LAN, il protocollo è gestito all’interno del router che assegna in maniera automatica ai dispositivi collegati ad una rete gli indirizzi IP, allo stesso tempo in teoria evita di duplicare uno stesso indirizzo IP per due dispositivi diversi tra loro aventi indirizzi MAC diversi. Inoltre, permette di esonerare gli utenti meno esperti dal doveroso compito della configurazione manuale dei dispositivi in una rete. In una classica rete locale domestica distinguiamo alcuni parametri molto importanti e da tenere bene a mente:
- IP (privato): serve a identificare i dispositivi connessi in una sottorete compreso quello del router. Nel caso di una rete LAN viene chiamato IP privato, per es: IP smartphone 192.168.0.5, IP notebook 192.168.0.4, IP router: 192.168.0.1 - 192.168.1.1;
- Subnetmask: definisce il range della sottorete e allo stesso tempo, maschera l’IP privato di un dispositivo alla rete WAN (internet), di solito corrisponde all’indirizzo IP 255.255.255.0;
- Gateway: riproduce l’IP del router 192.168.0.1 - 192.168.1.1 e svolge anche la funzione di portale tra la rete LAN e rete WAN (gate);
- Broadcast: serve per comunicare con tutti i dispositivi della sottorete e identifica l’interfaccia fisica ethernet del router, indirizzo IP: 192.168.0.0 - 192.168.1.0.
I pacchetti che viaggiano in rete locale si chiamano Frame Ethernet e sono strutturati in maniera leggermente diversa rispetto ai pacchetti TCP che viaggiano in internet. Cerchiamo ora di fare un po’ di chiarezza con un esempio:
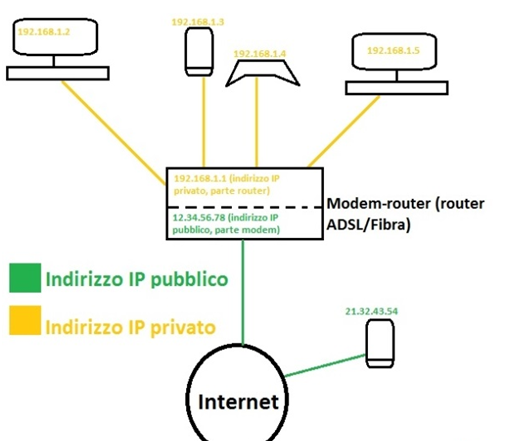
In una rete locale x, attraverso il meccanismo del DHCP del router avente indirizzo IP 192.168.1.1, su ogni dispositivo avente un proprio indirizzo Mac sarà assegnato un indirizzo IP privato e univoco che, oltretutto lo contraddistinguerà dagli altri dispositivi collegati alla rete stessa. Ad ogni dispositivo della rete x che accederà alla rete internet (wan) gli sarà assegnato dall’ISP di appartenenza in maniera dinamica o statica, un indirizzo IP pubblico. L’IP pubblico sarà identico per ogni dispositivo della rete locale che si collegherà alla rete internet, questo vuol dire che ogni client accederà in internet con lo stesso IP pubblico, ma all’interno della rete locale i dispositivi avranno indirizzi IP privati diversi grazie all’assegnazione automatica DHCP e quest’ultimi non saranno visibili in internet per merito del router che attraverso un meccanismo di NAT (Network Address Translation) riscrive in ogni pacchetto l’indirizzo ip sorgente delle richieste (source IP) settandolo come indirizzo ip pubblico mascherando quello privato (Subnetmask).

Spero sia chiaro questo concetto perché è importantissimo!
Fonte: Ebook Hackerpunk vol.1 profiling https://shorturl.at/jWZ06
Abbiamo visto in maniera generica i primi 4 layer del modello OSI, ora vediamoli secondo TCP/IP, la sostanza non cambia se non come già accennato per via della semplificazione e la riduzione dei layer.
I protocolli di rete come abbiamo visto nel paragrafo delle porte, sono regole d’ingresso e uscita da una rete, le troviamo contenute nei layer e validano le comunicazioni utilizzate principalmente tra computer collegati, mentre le porte di rete sono gli ingressi veri e propri gestiti dai router e rappresentati attraverso un numero identificativo, il loro scopo è quello di evitare problematiche di natura tecnica, tipo quelle di codifica e decodifica dei dati.
I protocolli e le porte di rete sono in stretta correlazione perché è solo grazie alla loro intesa che i servizi come e-mail, visualizzazione ipertesti, risoluzione nomi di dominio DNS, si risolvono tra i client e i server. Questo sistema garantisce che le comunicazioni vengano risolte senza problematiche: inoltre, ci permette di compiere contemporaneamente più operazioni simultanee senza che i servizi vadano in conflitto tra loro.
Un classico esempio di quello che ho appena detto è riuscire a guardare un film in streaming e contemporaneamente visualizzare le mail in arrivo sul vostro pc. Il protocollo di trasporto TCP non è unico, in alternativa si utilizza UDP, entrambi regolano il trasporto dei frame e la consegna dei pacchetti. Il TCP è più attento alla consegna dei pacchetti dati rispetto al protocollo UDP, garantisce la consegna e la ritrasmissione di pacchetti persi durante il processo di routing, gestisce il controllo degli errori e l'ordine di consegna dei pacchetti. A questo livello il pacchetto dati prende il nome di frame.
UDP non svolge questi controlli in quanto basa la sua attenzione sul tempo di trasmissione. In effetti il TCP per le funzioni di controllo sui pacchetti paga delle spese in termini di latenza e tempi più lunghi di ritrasmissione: un esempio di applicazione che adotta UDP è il media streaming. I protocolli secondari come: SMTP, HTTP, DNS, DHCP con le relative porte 80=HTTP, 53=DNS, 67=DHCP giocano invece un ruolo di ordinaria comunicazione all’interno delle applicazioni e servizi che utilizziamo ogni giorno con i nostri dispositivi:
80 / HTTP à richiesta pagina web
53 / DNS à richiesta dominio al server DNS
67 / DHCP à assegnazione automatica indirizzi IP
25 / SMTP à invio e ricezione posta elettronica
Fonte: Ebook Hackerpunk vol.1 profiling https://shorturl.at/jWZ06
Ogni singolo pacchetto IP inizia il suo viaggio verso la rete internet partendo dal livello più alto della pila TCP/IP ovvero il livello application. Ogni pacchetto subisce un’operazione detta incapsulamento, ovvero ogni livello della pila TCP/IP aggiunge delle informazioni al pacchetto dati che viene trasmesso.
Mentre il pacchetto procede verso i livelli più bassi della pila, ad ogni livello gli vengono iniettate informazioni importanti per il suo viaggio, come fossero aggiunti dei veri e propri moduli. Questo meccanismo permette ai router della rete dal quale transiteranno i pacchetti di ricostruire il percorso di rete dalla sorgente alla destinazione finale, riscrivendo di volta in volta l’indirizzo IP nell’header. Ogni pacchetto è numerato e questa proprietà permette al TCP di garantire la consegna ordinata considerando che il sistema a commutazione a pacchetto non prevede un percorso fisso come avviene nella rete di circuito telefonico, ma i percorsi sono casuali e i tempi di arrivo dei pacchetti a destinazione spesso non coincidono tra loro.
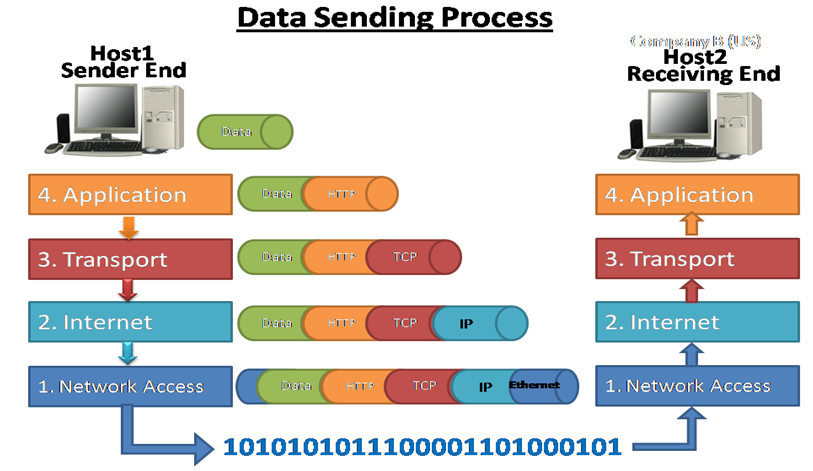
Ogni pacchetto IP viene “etichettato” con delle segnature, chiamate Header: le potremmo immaginare come delle postille inserite sulle classiche raccomandate postali. Le varie sezioni di un pacchetto TCP/IP sono strutturate in questo modo:
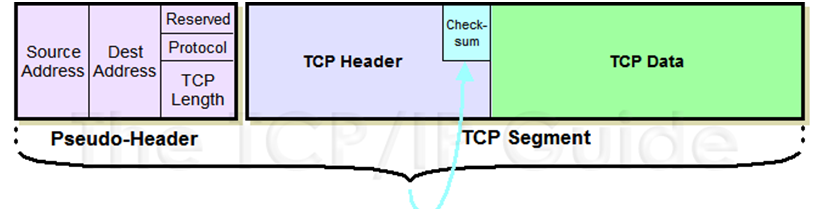
- Header: contiene tutte le informazioni necessarie alla trasmissione – indirizzo IP mittente e indirizzo IP destinatario;
- Data: contiene i valori da trasmettere, inerenti al messaggio di testo o un file;
- Checksum: è un codice di verifica dell’integrità del pacchetto. Infatti, qualora durante il tragitto nel processo di Routing un pacchetto venisse danneggiato, verrà utilizzato il valore checksum per la verifica e il rinvio del pacchetto non consegnato. Questo parametro, considerata la natura del protocollo, è utilizzato maggiormente dal TCP piuttosto che da UDP;
- Pseudo-Header: riguarda le informazioni iniettate ai vari livelli della pila.
Una volta che il pacchetto giunge al livello di rete, si innesca un secondo meccanismo regolato inizialmente dal protocollo IP e dal livello successivo TCP, il Routing. Esso non è altro che un vero e proprio flusso di pacchetti instradati su percorsi di rete diversi e contenenti parti dell’informazione iniziale: il tutto è gestito dai router sparsi per internet che recapitano ogni pacchetto al destinatario finale della richiesta (es. un server che ospita un sito web, un client/pc di un vostro amico), evitando oltremodo, attraverso continue variazioni di percorso, eventuali intoppi derivanti da guasti o errori tecnici lungo il tragitto.
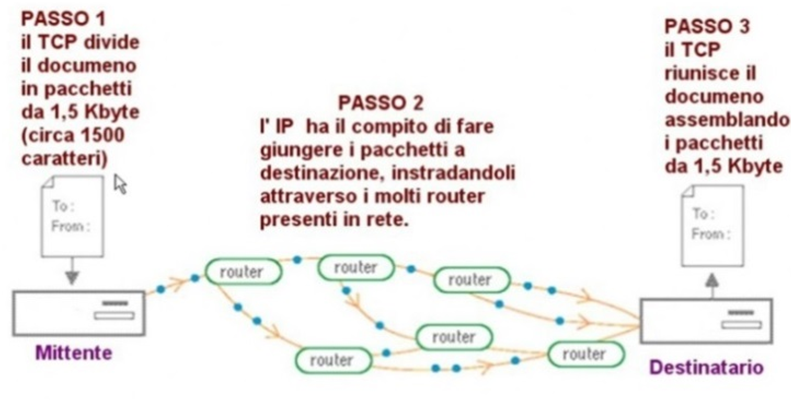
Giunto a destinazione, il pacchetto dovrà invertire necessariamente il meccanismo dell’incapsulamento e risalire la pila dal layer più basso (phisical) fino al layer più alto (application): infatti, dall’interno del pacchetto saranno letti e rimossi i pseudo-header aggiunti in precedenza fino ad ottenere il pacchetto originale contenente il vero valore trasmesso dal mittente della comunicazione che sarà letto finalmente dal destinatario.
Il protocollo di rete IP è chiamato protocollo senza connessione: il motivo è che a differenza del protocollo di trasporto TCP non garantisce la regolare consegna dei pacchetti, ma consiste solo in un indirizzamento via indirizzo IP. Questo è il motivo per cui il TCP ha bisogno dell’IP per identificare i router della rete in modo da instradare regolarmente i pacchetti, allo stesso modo l’IP ha bisogno del TCP per garantire la riconsegna dei pacchetti che potrebbero perdersi lungo il percorso.
Fonte: Ebook Hackerpunk vol.1 profiling https://shorturl.at/jWZ06
Il protocollo sul quale è costruita la rete internet è Internet Protocol Suite ovvero il TCP/IP. Il funzionamento di internet a livello fisico (commutazione di rete telefonica) se lo giocano fondamentalmente due tipologie di aziende:
- Carrier: sono le centrali di commutazione e forniscono il trasporto di dati a lungo raggio di tipo internazionale e intercontinentale sfruttando le relative dorsali (backbone);
- Provider: ISP (Internet Service Provider), forniscono la connettività Internet all’utente finale. I provider hanno collegamenti stabiliti ad alte prestazioni verso la rete di altri provider di grado uguale o superiore e a loro volta verso le dorsali dei carrier. Le dorsali o dette anche backbone definiscono i percorsi delle trasmissioni tra le centrali di commutazione ad altre centrali di commutazione (SGU) stati di gruppo urbano
Lo standard TCP/IP è un insieme di protocolli a livello software, sui quali si basa il funzionamento della gestione del trasporto e della consegna del pacchetto dati, è lo schema di trasmissione del sistema a commutazione di pacchetto.
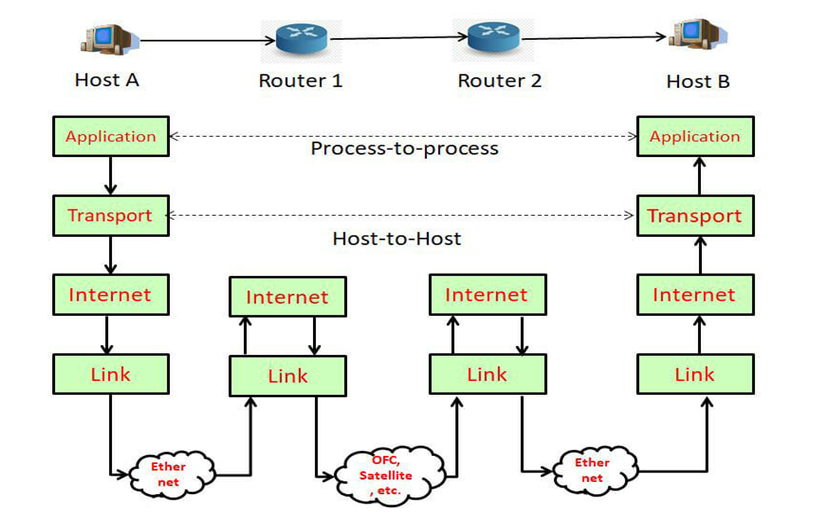
Ogni operazione di trasmissione, che sia una richiesta http, un’e-mail o un upload o download di una foto, il dato viene suddiviso in parti di memoria di dimensioni ridotte chiamate appunto pacchetti. Ogni singola informazione trasmessa per essere consegnata viene strutturata in frammenti di memoria che devono sottostare ad un insieme di regole (protocolli del TCP/IP). I pacchetti partono dall’applicazione sul dispositivo del mittente (4° layer application), seguono il loro corso verso i layer più bassi della pila e, giunti a livello internet, vengono trasmessi all’indirizzo IP del nostro router e a seguire nel layer data link in rete locale.
Attraverso un processo che si svolge proprio all’interno del vostro router e di tutti i router della rete, chiamato Routing i pacchetti vengono immessi in internet in maniera del tutto casuale. Tutti i router operano a livello 3 OSI, ogni layer comunica con il suo pari nel percorso di transito fino alla destinazione proseguendo la scalata fino al layer application del destinatario.
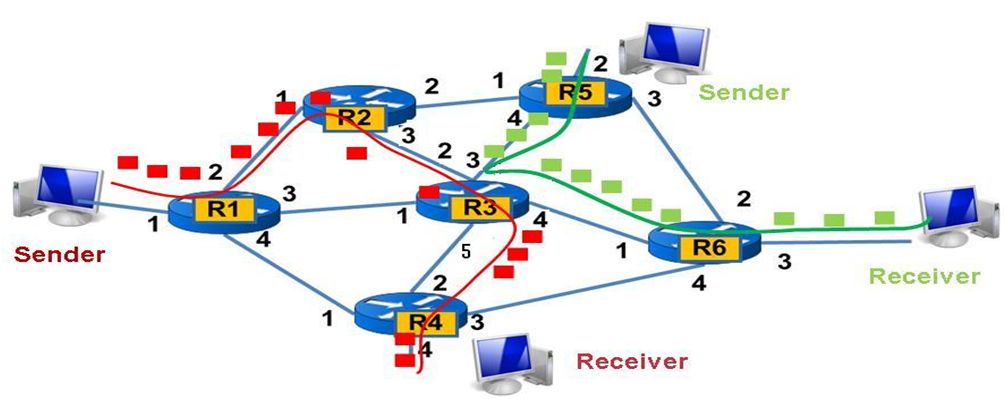
Attraverso il routing si decide per i pacchetti dati qual è il percorso d’instradamento ottimale in internet al fine di raggiungere in maniera più rapida possibile la destinazione finale. Il sistema fa uso di routing table, algoritmi che calcolano il percorso migliore in tempi più brevi e con minore percentuale di imprevisti derivanti, per esempio, da guasti lungo il percorso, router non funzionanti, cavo fibra tagliato, ore di punta, collisione di pacchetti o altri imprevisti. Qualsiasi dispositivo elettronico dotato di una scheda di rete collegata ad un router gli viene assegnato dall’ISP al quale è abbonato un indirizzo IP che, come già accennato in precedenza, gli consenta di distinguerlo univocamente dagli altri dispositivi nella rete internet senza essere in nessun modo replicato, in maniera simile ad un indirizzo di residenza nel web.
Esistono due autorità a livello mondiale che gestiscono le assegnazioni degli indirizzi IP:
- IANA (Internet Assigned Numbers Authority) regola l’assegnazione degli indirizzi IPV4 e IPV6;
- ICAN (Internet Corporation for Assigned Names and Numbers) regola la gestione dei server DNS domain name system.
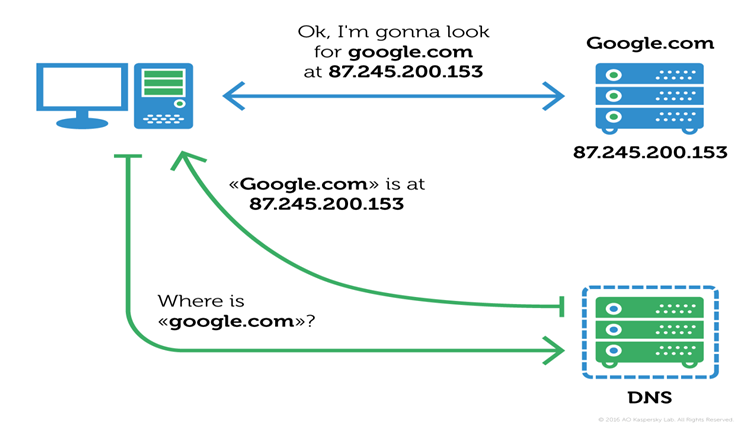
Ogni internet service provider acquista un range d’indirizzi IP dalla IANA e li assegna in maniera dinamica ai propri abbonati collegati in rete con i relativi dispositivi. Agli arbori della rete internet. quando i siti web si contavano sulla punta delle dita, per collegarsi ad un sito web si digitava il codice dell’indirizzo IP in questo modo: 155.256.21.21 Una situazione del genere, proiettata ai giorni nostri in una rete globale che incorpora miliardi di siti web, ricordare a memoria gli indirizzi IP di ogni web server potrebbe creare non pochi problemi.
Per fortuna in soccorso a questa situazione sono nati i DNS server, che, nel tempo, hanno portato ad una enorme semplificazione delle comunicazioni. L’utilizzazione degli indirizzi di rete è stata notevolmente agevolata grazie all’indirizzamento simbolico per domini, una funzione che assegna un nome simbolico al suo indirizzo IP. Le assegnazioni sono gestite dai DNS server, ai quali i browser degli utenti si collegano costantemente per risolvere le associazioni richieste dall’indirizzo URL che digitiamo nella barra degli indirizzi. Un semplice esempio aiuterà a capire meglio ill concetto: un utente digita sul proprio browser l’indirizzo del sito web di Google in questo modo: http://www.google.com, esso corrisponderà all’indirizzo IP 64.233.167.99, questa associazione 64.233.167.99 --> google.com è stata recuperata dal un server diverso di quello di destinazione che, in particolare, gestisce le richieste di dominio. Questo caso rappresentato è solo uno delle migliaia di relazioni salvate sui DNS server che ogni minuto vengono gestite dai DNS server.
Fonte: Ebook Hackerpunk vol.1 profiling https://shorturl.at/jWZ06
Quando digitiamo un indirizzo URL nella barra degli indirizzi del browser non facciamo altro che richiedere un servizio al web server, che corrisponde, come abbiamo già visto, all’indirizzo IP generato con il meccanismo del reverse DNS. In genere si richiede la visualizzazione del codice html che sarà successivamente tradotto dal nostro browser in una pagina web. Questo tipo di richieste avvengono tramite il protocollo http sulla porta 80 e sulla sua variante cifrata https sulla porta 443. Una semplice richiesta ad un web server per la richiesta di una pagina web può essere così tradotta:
COMPUTER: richiesta pagina web
- L’indirizzo letterale inserito nel browser https://www.google.com:443 è risolto in un indirizzo IP tramite la gestione dei server DNS, la porta 443 può essere omessa poiché viene sottointesa e inserita in maniera automatica dal browser.
- È inviato un pacchetto IP contenente una richiesta http al web server, le informazioni nell’header del pacchetto nel caso di richieste https sono cifrate e non viaggiano in chiaro: questo è merito del certificato SSL/TLS utilizzato dal protocollo https.
- Il web server è generalmente indicato da www (word wide web) seguito dal dominiosito.it e dalla porta utilizzata dal protocollo (opzionale).
WEB SERVER: risposta alla richiesta
- Il web server riceve la richiesta e risponde al browser con un pacchetto IP contenente i dati https di risposta, tra i quali il codice in linguaggio html del sito web richiesto.
- Il browser del dispositivo mittente visualizza il sito web sullo schermo
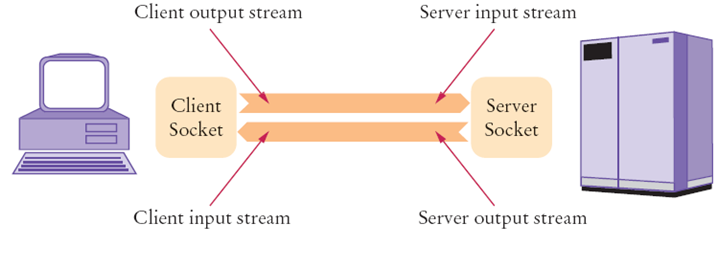
Il socket di rete non è altro che un software che consente lo scambio di dati tra host remoti o tra processi locali, identifica il punto terminale di una connessione a doppio senso tra due interfacce client e server in ambito rete LAN o Wan. In termini pratici, il socket è definito in questo modo:
socket = indirizzo IP: numero porta
(Es: 125.156.156.156:80)
Tecnicamente, per recuperare un qualsiasi oggetto o risorsa in rete (file, documento, immagine) è necessario conoscere almeno due informazioni:
Dove è situato?
Nome della macchina, percorso hard disk, nome file.
Con quale protocollo?
Il protocollo utilizzato dal servizio che lo gestisce per essere recuperato.
Per racchiudere in un unico indirizzo tutte queste informazioni è stato ideato uno schema che prende il nome di URL (Uniform Resource Locator), che assume la seguente struttura:
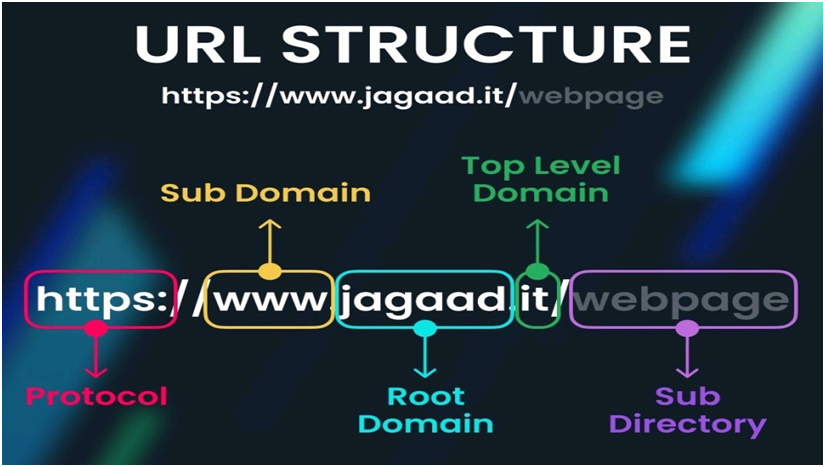
http://hackerpunk:80/index.html
Protocollo://Dominio-ip:Porta/NomeRisorsa.estensione
Con il passare degli anni il sistema url con i relativi meccanismi e metodi utilizzati per gestire delle risorse in internet (http verbs: GET, POST, PUT, DELETE), ha generato la creazione di un nuovo standard sfruttato da particolari web application chiamato: REST (Representational State Transfer) e il relativo sviluppo applicativo dell’infrastruttura associata API Application Programming Interfaces (REST APIs).
Le API contengono un insieme di procedure in genere costruite su librerie software finalizzate al recupero di risorse tramite l’indirizzo URL. Un classico esempio di utilizzo sono i widget.
Le richieste e risposte http generano l’invio di pacchetti dati e come già spiegato contengono gli header.
Prima di esaminare i request header e i response header di un pacchetto IP nelle richieste http fatte ad un web server, è doveroso ridordarvi che ogni client esegue alcuni processi di connessione TCP socket di tipo sicuro è affidabile, il processo a 3 vie che garantisce affidabilità prende il nome di Syn - Syn/Ack -Ack ovvero in ogni fase vi è un invio di pacchetti contenenti dei valori casuali che stabiliscono l'autenticità e la conclusione di una connessione TCP. Questi meccanismi come anche il “client/server Hello” che avviene nelle comunicazioni cifrate dal certificato TLS sono utili nel stabilire affidabilità e sicurezza nelle trasmissioni web, nel caso del processo Syn/Ack si garantisce affidabilità di avvenuta consegna di tutti i pacchetti giunti al server destinatario controllando oltremodo se qualcuno si è perso nel routing e se necessita di un rinvio. Il processo di Syn-Ack non avviene per il protocollo di trasporto UDP, il che lo rende appunto inaffidabile per alcuni protocolli di comunicazione mentre più efficace nello streaming di dati e richieste DNS. Anche se ancora in via sperimentale è importante citare il protocollo di sicurezza per le query web che sta sviluppando Google, noto come QUIC, si basa sul protocollo di trasporto UDP (con funzione di check) e mirerà a sostituire i certificati TLS perché racchiude in se sia il processo di Syn-Ack che quello di Client hello.
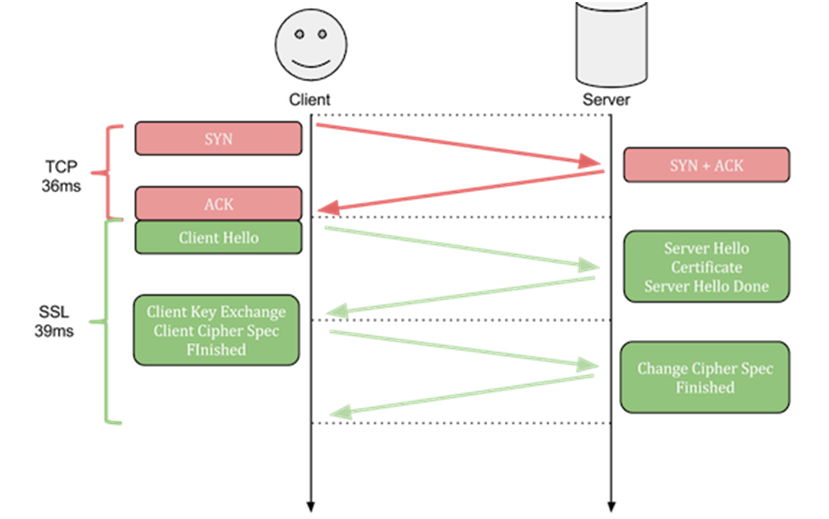
Ritornando alle request http, all’interno degli header dei pacchetti sono specificate tutte le informazioni necessarie utili per il buon esito della comunicazione con il server. L’header rappresentato nel riquadro verde di seguito rappresenta una richiesta al web server utilizzando il protocollo http (senza i controlli visti prima) che avverrebbe in tal caso in ordine subito dopo il Syn/Ack per richieste http e dopo Syn-Ack e Client Hello per richieste https.

Possiamo notare che nel request header sono contenute le seguenti informazioni:
REQUEST HEADER

La prima riga request line contiene il metodo utilizzato GET, nel nostro esempio è una keyword appartenente ad una richiesta http: se fosse stata una richiesta https (cifrata) il metodo sarebbe stato POST. Queste due paroline chiave sono molto importanti, indicano se le informazioni che viaggiano all’interno dell’URL devono essere o meno cifrate attraverso le procedure di crittografia dei certificati che usa il protocollo https ovvero SSL/TLS.
Dopo la request line ci sono sei request header, il numero di request header può essere variabile in base al tipo di richiesta effettuata e incomincia sempre con il nome della request stessa seguito dal “:”, da uno spazio e dal valore associato all’header.
Senza impararle a memoria, le principali request header sono:
- Accept: specifica l’ordine preferito dal browser relativamente ai MIME types supportati, il valore “*/*” indica che il browser è in grado di gestire qualunque tipologia di MIME type;
- Accept Encoding: specifica le tipologie di compressioni accettate dal browser;
- Accept Charset: specifica l’insieme di caratteri che il browser può accettare;
- Accept Language: serve a specificare i codici di linguaggi standard che il browser preferisce ricevere;
- Authorization: identifica il livello di autorizzazione per il browser;
- Cookie: specifica i valori di eventuali cookie inviati al server nelle precedenti comunicazioni con il browser;
- Host: contiene informazioni sull’host e la porta utilizzata;
- Referer: indica l’URL della pagina web a cui fa riferimento;
- User-agent: indica il tipo di browser. Un bug ancora noto è che internet explorer viene identificato come mozilla, per ovviare a questo errore gli viene assegnato una stringa “MSIE” per distinguerlo dal browser di Firefox.
RESPONSE HEADER
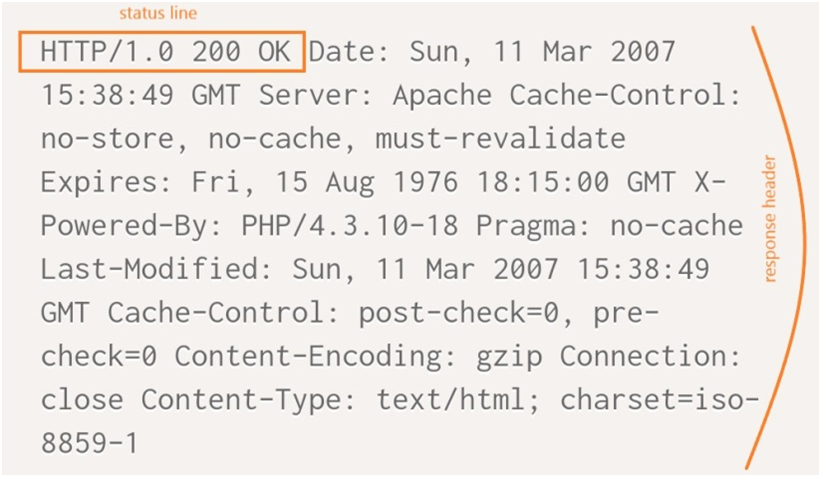
La prima riga, di una response HTTP, viene chiamata status line. In essa vengono specificate:
- la versione del protocollo HTTP che si sta utilizzando (http/1.0);
- un codice definito status code (nel nostro caso valorizzato con 200);
- un messaggio associato allo status code (“OK”).
Dopo la status line, sono presenti le response header, contenenti delle informazioni sul server e sulla risposta che si sta inviando al client. Ogni response header inizia con il nome dell’header seguito dal carattere “:”, uno spazio e il valore associato all’header.
Le principali response header utilizzate sono:
- Cache-control: controlla la modalità di caching per una pagina web;
- Content-disposition: può essere utilizzato per specificare un file binario in allegato alla response;
- Content-length: specifica la lunghezza del body della response, espresso in byte;
- Content-type: specifica il MIME type del documento di risposta;
- Content-encoding: specifica il tipo di codifica utilizzato nella risposta. Spesso, utilizzare una codifica di tipo GZIP incrementa notevolmente le performance;
- Expires: specifica la durata della cache;
- Last-modified: indica, in termini temporali, l’ultimo aggiornamento effettuato su una pagina;
- Pragma: disabilita la cache sui vecchi browser attraverso l’utilizzo della stringa “no-cache”;
- Refresh: specifica il numero di secondi trascorsi i quali il browser deve richiedere un aggiornamento della pagina
Per maggiori dettagli sulle request e sulle response header si rimanda alla RFC specifica (2616).
Al termine dell’ultima response header si ha una riga vuota seguita dal cosiddetto response body che, tipicamente, è il contenuto HTML del documento (<html>codice del sito web</html>).
Fonte: Ebook Hackerpunk vol.1 profiling https://shorturl.at/jWZ06
L’accesso a internet fornisce indiscutibili benefici per le aziende, le organizzazioni e anche per i privati. D’altro canto, però ciò consente anche al mondo esterno di poter raggiungere sia i personal computer e sia i sistemi presenti su una rete interna composta da una varietà di dispositivi con caratteristiche anche diverse (sistemi operativi diversi, dispositivi differenti, ecc).
Una soluzione alternativa o, perlomeno, complementare alla sicurezza, basata sui servizi presenti su ciascun host, è costituita dal Firewall.
Il firewall è un componente software che risiede in senso logico nel router: la sua utilità è quella di proteggere la rete interna da attacchi provenienti da internet e fornire un unico punto di accesso in cui imporre la sicurezza e la registrazione degli auditing.
Il firewall può essere un singolo sistema informatico oppure due o più sistemi che cooperano per svolgere tale funzione. Definire adeguate policy di accesso nel firewall è un aspetto cruciale. Le policy definiscono il tipo di traffico autorizzato a passare attraverso il firewall in modo da permettere il filtraggio sulla base di alcune definizioni di parametri:
- il range di indirizzi IP e la direzione del flusso;
- il tipo di applicazione;
- l’identità degli utenti;
- l’attività di rete (evitare lo spam o port scanning);
- il tipo di contenuti.
Il firewall non è la porta sbarrata dalla quale non si passa per nessuna ragione, i pacchetti IP derivanti da un eventuale attacco da parte di un malintenzionato dovranno passare attraverso il firewall ed eventualmente in base alle policy attuate il sistema di IPS (Intrusion Prevention System) chiuderà la porta dalla quale è passato in modo da non permettere la comunicazione di raggiungere l’esterno dalla rete locale. Questo sistema ha dei limiti:
- non può proteggere da attacchi o da traffico su connessioni che l’oltrepassano, per esempio da una configurazione non adeguata di policy;
- non può proteggere da minacce provenienti dall’interno della rete che sta proteggendo.
Alcuni casi riferiti a quest’ultimo possono derivare da un dipendente insoddisfatto chiamato insider, che coopera inconsapevolmente con l’hacker o da dispositivi (laptop, chiavi usb) che, infettati da virus, sono utilizzati nella rete interna per scopi malevoli.
Senza entrare troppo nei tecnicismi esaminiamo ora per completezza la funzionalità di filtraggio dei pacchetti IP di alcune delle principali tipologie di firewall.
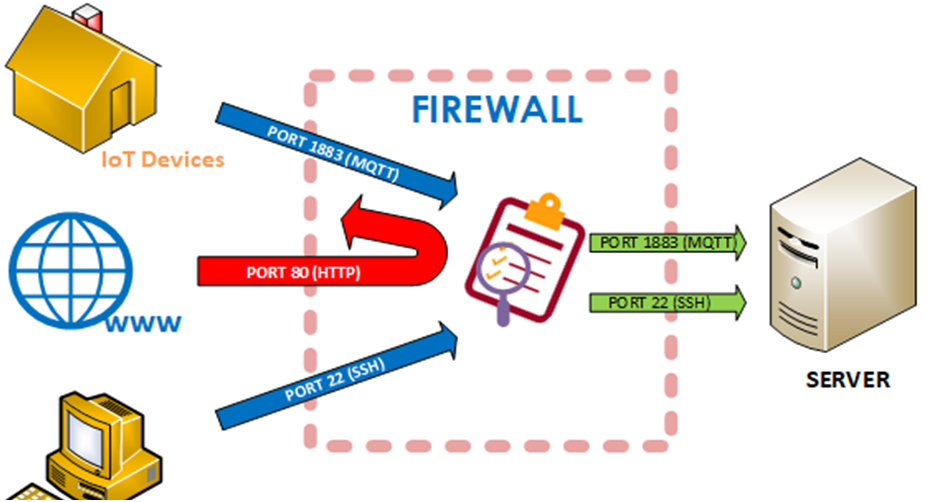
L’attività di filtraggio di pacchetti IP (packet filter firewall) avviene sui pacchetti di rete in base a:
- Indirizzo IP sorgente/destinazione;
- Numero di porta a livello di trasporto che definisce una specifica applicazione (porta 25 per la posta elettronica);
- Campo del protocollo IP che definisce il protocollo di trasporto.
Le tipologie di firewall più innovativi sono chiamati NGFW (Next Generation Firewall) e si basano su:
- Comportamenti del pacchetto: Behavior –Based detection
Analizzano come si sta comportando un determinato pacchetto all’interno di una comunicazione, IDS (Intrusion Detection System) è un altro sistema che confronta i comportamenti in passato avuti da un pacchetto malevolo all’interno della rete aziendale o all’interno di altre reti aziendali recuperando tali dinamiche all’interno di database condivisi e li comunica all’IPS/firewall;
- Signature: Signature –Based detection
Analizzano il pacchetto in base a qualcosa di scritto, un’impronta digitale (hash del file) che permette il maching (confronto) tra la firma del file e la firma presente in un database condiviso.
I firewall NGFW, come anche altre tecnologie, sono ormai orientate al concetto di Precognition, ovvero previsioni comportamentali del pacchetto grazie ai sistemi ad intelligenza artificiale.
Fonte: Ebook Hackerpunk vol.1 profiling https://shorturl.at/jWZ06
Neque porro quisquam est, qui dolorem ipsum quia dolor sit amet, consectetur, adipisci velit, sed quia non numquam eius modi tempora incidunt ut labore et dolore magnam aliquam quaerat voluptatem. Ut enim ad minima veniam, quis nostrum exercitationem ullam corporis suscipit.